First off I should own up to something, I've been on the Java SE 6 JSR group but I'm going to comment only on the publicly available information, but don't expect it to change too much.
Secondly I've got a few prejudices about development, these come from broadly three sources
1) The Mythical Man Month
2) Having Ada, Eiffel and C as my first three "commercial" languages
3) Working on projects with tens, or even hundreds of developers
So Java SE 6 is now in beta, and its got lots and lots of "cool features" to attract the Slashdot crowd. As someone whose applications are mainly
1) Developed by lots of people in different countries
2) Expected to be maintained for years by different people
3) Run remotely on Servers
This means that what I use are things like J2EE, Spring, Struts and all those application container frameworks out there. I'm used to selecting the technology mix that we will use on the project and picking the 3rd parties libraries, products or projects that will be used. And when selecting those technologies one of my major considerations is how to LIMIT functionality being used in the wrong way.
What I have problems with is "clever" developer code that is a bugger to maintain, and people going for the Shiny Nickel Anti-pattern, and using things because they are "in the specification" so they must be right. The other problem I have is that underneath my nice application container there are a huge raft of Java standard libraries that not only don't I need, but which I definitely don't want being called (Midi sound from J2EE anyone?).
So what are the highlights of Java SE 6?
Security - Kerberos, JAAS & Smart Card. Well if I've got J2EE then I've got this already, if I've got Spring its not exactly a leap, so no bonus here.
Integrated Web Services - Oh great, because it was SO hard to use Axis or Web Services in J2EE anyway. Worst of all this doesn't just mean CALLING web-services, it includes call-backs, that's right folks every single Java application will have a Web Server embedded in it with Java SE 6. I can see security people all over the world updating their recommendations on Java for the desktop. This is before we get to the challenge of doing asynchronous programming in a standard Java app, a problem that makes multi-threading (which most people can't do) look simple.
Enhanced Management - Now includes a bit more monitoring and a link to Solaris, whoopee.
Increased Developer Productivity - Absolutely rubbish, everything that has gone in is around bells and whistles, there is nothing about helping developers, putting in async coding models is about as far away from productivity as you can get. There are no elements for instance that help IDEs work better with Java, nor are there any elements that add more productive language features.
Improved User Experience - Great some desktop improvements, what a huge bonus on my remote server.
Missing off the list is my personal "favorite" which is the scripting support, and to top this for Sun this means bundling JavaScript as a language. This Java SE release effectively recommends heterogeneous programming as a good thing and that scripting is something to be embraced on your project. I'm not a huge fan of scripting, I'd put it in the multi-threaded code perspective, there are about 2% or less of developers I'd trust to do it well, its not something I want "clever" developers putting in because they think its cool.
So with Java SE 6 its now official that Microsoft were right (and the DoD and language research people wrong) that multi-language development is a good thing(tm).
This is a kitchen sink Java SE release where lots of libraries that could have been downloaded separately have been integrated into the basic platform. Unlike every previous Java release where there has been a good mix of enterprise requirements and some populist elements, this release is purely for the populist with only problems for the enterprise. Its bigger and more bloated, now featuring a whole new language (JavaScript) a Web Server and yet more libs for pretty GUIs.
The good news is that Java SE 7 might focus more on the multi-billion dollar market than the Slashdot crowd.
Its about time that Enterprise Java projects, whether in Spring, Java EE or whatever had a basic Java platform that doesn't include all the crap aimed at creating a platform that "proudly" boasts more bells and whistles than .NET. In the same way as having GUI code in the kernel of an operating system is a bad idea(tm), its a dumb idea for the Java core.
We need a core platform that just includes the basis, we need a Java Desktop version that includes the GUI. Enterprise projects can then just use the extras that they want, and not have to cope with the crap that they don't. With SWT and the like being used more often its time to admit that some people might not want all those Swing libraries. Almost exactly what Sun do already and no I don't know what that isn't a sensible strategy either.
Time to start lobbying for Java SE 7 code named Dolphin - the enterprise release?
* - bad idea(tm) is a trademark of Microsoft Corp
Thursday, March 30, 2006
Friday, March 24, 2006
Anatomy of a Service Project - Part 2
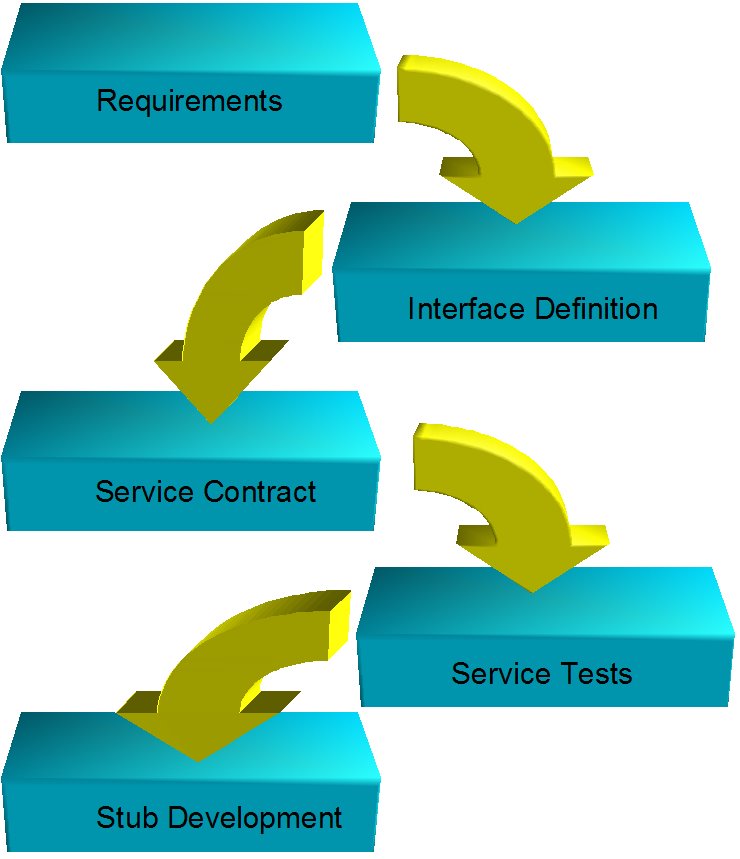
The first iteration of a service project should be slightly different to the rest, while the aim of future iterations is to create functionality the aim of the first iteration is to define the interface, contract, tests and a stub. The purpose of this iteration is two fold
- Formally define what the service is
- Interface is what other services need
- Contract defines how it should operate
- Tests prove that it operates in that way
- Provide something for others to call
There are a few rules for the stub
- It should reliably succeed or fail
- It shouldn't do any real business logic
- It shouldn't call anything else
There are abilities to think about services as Mock Objects and all of those challenges, but that is really the job of the people calling the service to work out what they need. This leads to an interesting situation, other services will create mock versions of YOUR service to test against, this helps build the testing library based on their requirements rather you trying to create them.
So that finishes iteration 1, all that is required is to deploy the service to the test environment so others can start "using" it.
TBC...
Thursday, March 23, 2006
Anatomy of a Service Project - Part 1
So if we are going to move to Service projects what would a service project look like? What is the plan for Service projects, what do you do first, what are the important principles?
Well first off you need to do the basics, Services don't mean you can ignore the standard good practices this means
Before the Service Project starts you need to know what the Service is, this comes from the Service Oriented Architecture work that you will have done earlier to define the services you actually need, this will have created a service definition which describes the primary tasks and purpose of the service, and if you are lucky links to the actual objects being used. So at a top level we have a pretty simple process for our service project
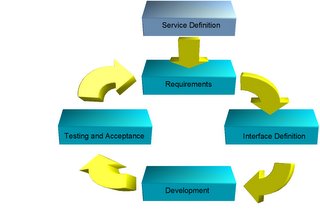 Not much different to a normal project in fact, the only bit that gets more important is the interface definition.
Not much different to a normal project in fact, the only bit that gets more important is the interface definition.
So a service project is defined from the service architecture, applies standard best practices and makes the definition of the service interface a critical element in the process. Certainly not rocket science. It can be developed in a single iteration, or as many rapid iterations.
As with all decent project approaches a key practice is to attack the highest risk items first, with a service this is most normally the service interface as it has the largest external impact if it needs to change, what you want is to get to a relatively static interface as quickly as possible, future iterations then consider the policy and governance aspects of the interface rather than the actual calling semantics.
TBC...
Well first off you need to do the basics, Services don't mean you can ignore the standard good practices this means
- Iterations - Iterative delivery is NOT "agile", its just plain good delivery.
- Testing - Unit Tests, System Tests, automated
- Requirements - defined, managed and tracked
- Quality - metrics, tracking, code reviews
- Version Control - all artifacts managed and tracked
- etc etc etc
Before the Service Project starts you need to know what the Service is, this comes from the Service Oriented Architecture work that you will have done earlier to define the services you actually need, this will have created a service definition which describes the primary tasks and purpose of the service, and if you are lucky links to the actual objects being used. So at a top level we have a pretty simple process for our service project
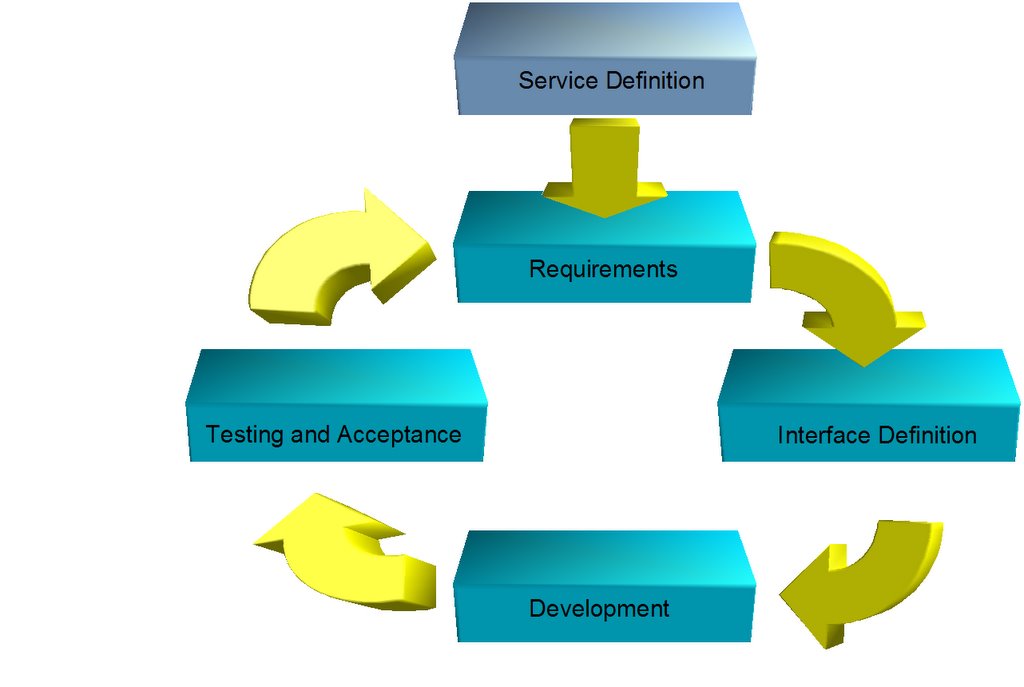 Not much different to a normal project in fact, the only bit that gets more important is the interface definition.
Not much different to a normal project in fact, the only bit that gets more important is the interface definition.So a service project is defined from the service architecture, applies standard best practices and makes the definition of the service interface a critical element in the process. Certainly not rocket science. It can be developed in a single iteration, or as many rapid iterations.
As with all decent project approaches a key practice is to attack the highest risk items first, with a service this is most normally the service interface as it has the largest external impact if it needs to change, what you want is to get to a relatively static interface as quickly as possible, future iterations then consider the policy and governance aspects of the interface rather than the actual calling semantics.
TBC...
Monday, March 20, 2006
Choose an ESB topology to fit your business model
IBM have written an article on how to Choose an ESB topology to fit your business model some of the bits are pretty good, but its also like a project management method article that starts by pushing waterfall. The first item up is the Single Global Company model which provides effectively a single ESB even if its actual deployed federated.
What they really don't cover in any depth is the differing requirements of business objective and integration that the different ESB products attempt to solve. Its a decent article in the problems it raises, if it does make the mistake of assuming (beyond a very light governance section) that technology is the primary saviour. The solutions are really re-workings of traditional EAI solutions rather than looking objectively at Service Oriented problems. Picking on the brokered ESB pattern, where it is suggested that a broker is required to provide the bridge, it is liable to be simpler to manage if its done via policy on a source bus which chooses which service are made external across bus boundaries.
Its a good article in highlighting the problems and challenges that inherently happen because a single ESB is not a viable solution in any non-trivial organisation. But I'd argue that its more an EAI pattern article re-badged for ESB than a set of patterns aimed at business Service challenges, in paticular they don't stress use of policy and governance as a mechanism over older EAI approaches.
What they really don't cover in any depth is the differing requirements of business objective and integration that the different ESB products attempt to solve. Its a decent article in the problems it raises, if it does make the mistake of assuming (beyond a very light governance section) that technology is the primary saviour. The solutions are really re-workings of traditional EAI solutions rather than looking objectively at Service Oriented problems. Picking on the brokered ESB pattern, where it is suggested that a broker is required to provide the bridge, it is liable to be simpler to manage if its done via policy on a source bus which chooses which service are made external across bus boundaries.
Its a good article in highlighting the problems and challenges that inherently happen because a single ESB is not a viable solution in any non-trivial organisation. But I'd argue that its more an EAI pattern article re-badged for ESB than a set of patterns aimed at business Service challenges, in paticular they don't stress use of policy and governance as a mechanism over older EAI approaches.
Tuesday, March 14, 2006
SOA Project Management - killing Waterfall one step at a time
One of the saddest facts in IT is that Waterfall project management, something agreed for probably over 20 years to be a bad thing, is still not only in existence but thriving. Brilliantly parodied by the Waterfall 2006 conference its just amazing how often people fall back into this "learnt" behavior that Waterfall is somehow safe.
A quick wander around finds some waterfall pictures that show the wonder of the process
 and (from the same site) the wonderful phrase
and (from the same site) the wonderful phrase
"The traditional or waterfall methodology is the forefather of all other methodologies and we find it is most suitable for projects where the requirements are clearly stated and static or where it helps to have a rigid management structure."
Sorry to pick on the folks but it was the first one from Google I could find, and they do also mention DSDM. But really "requirements are clearly stated and static"... the management argument is pure rubbish as Waterfall's management approach is basically wait till the end to identify issues, this isn't a rigid management structure. And there are other crackers around "If you are working on a somewhat traditional project (for instance, an accounting system) where the features are defined a priori and it's possible to freeze the specification, the waterfall process is your best bet." which is the FIRST bloody thing on the page. Are people really in such a head in the sand belief that Waterfall actually delivers what is wanted and is the best approach, that requirements WILL NEVER change, and that the screens you designed on paper will work the way the users imagined?
So quite clearly its pointless trying to change everyone in the world in one go, we have to face the reality that Waterfall project management is out there and pushed and praised "I believe most, if not all projects, can be delivered with the waterfall methodology". This is good old Fred Brooks Mythical Man Month territory, and if Fred says its wrong its wrong. Given that, and in order to make our SOA projects actually work we need to "fake" waterfall.
Fortunately SOA gives us a way to do that, it helps us turn big projects into Programmes which has two benefits
So each Service project will still look "Waterfall" but will be small enough hopefully for Waterfall to cope.
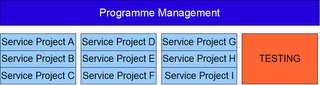 This is and example of a 9 service project in this sort of approach. Some of these services will be business services, some will be technical, and of course the highest risk elements should come at the start. Unfortunately we still have the massive tailend of Testing to worry about which is where the concept of "Project UAT" can come in, the approach here is to sell UAT for each project as an increase in formalism, so getting people testing earlier is all about adding extra process to the project. The reality is of course that this testing reduces your risk as you are getting eyes on the solution earlier. This can then be used to either reduce the testing at the end, or demonstrate your genius by waltzing through it without an issue.
This is and example of a 9 service project in this sort of approach. Some of these services will be business services, some will be technical, and of course the highest risk elements should come at the start. Unfortunately we still have the massive tailend of Testing to worry about which is where the concept of "Project UAT" can come in, the approach here is to sell UAT for each project as an increase in formalism, so getting people testing earlier is all about adding extra process to the project. The reality is of course that this testing reduces your risk as you are getting eyes on the solution earlier. This can then be used to either reduce the testing at the end, or demonstrate your genius by waltzing through it without an issue.
Lets be clear though, I'm not advocating this as the best approach, just as a way to get Waterfall project managers and organisations working in a more iterative way using Services as the mechanism. Its not rocket science and its not ideal but until there are no more muppets posting things about Waterfall being an option and I stop seeing projects being delivered in a waterfall way its at least better that what was there before. And if you can keep all your waterfall projects inside a month then its hard to tell the difference from agile.
A quick wander around finds some waterfall pictures that show the wonder of the process
and (from the same site) the wonderful phrase"The traditional or waterfall methodology is the forefather of all other methodologies and we find it is most suitable for projects where the requirements are clearly stated and static or where it helps to have a rigid management structure."
Sorry to pick on the folks but it was the first one from Google I could find, and they do also mention DSDM. But really "requirements are clearly stated and static"... the management argument is pure rubbish as Waterfall's management approach is basically wait till the end to identify issues, this isn't a rigid management structure. And there are other crackers around "If you are working on a somewhat traditional project (for instance, an accounting system) where the features are defined a priori and it's possible to freeze the specification, the waterfall process is your best bet." which is the FIRST bloody thing on the page. Are people really in such a head in the sand belief that Waterfall actually delivers what is wanted and is the best approach, that requirements WILL NEVER change, and that the screens you designed on paper will work the way the users imagined?
So quite clearly its pointless trying to change everyone in the world in one go, we have to face the reality that Waterfall project management is out there and pushed and praised "I believe most, if not all projects, can be delivered with the waterfall methodology". This is good old Fred Brooks Mythical Man Month territory, and if Fred says its wrong its wrong. Given that, and in order to make our SOA projects actually work we need to "fake" waterfall.
Fortunately SOA gives us a way to do that, it helps us turn big projects into Programmes which has two benefits
- Helps us get SOA projects into iterations by default
- Makes the Project Manager feel important by calling them a programme manager
- Small team delivery - max of 4 - ideal of 2
- Short delivery timeline - max of 60 working days - ideal of 20 working days
So each Service project will still look "Waterfall" but will be small enough hopefully for Waterfall to cope.
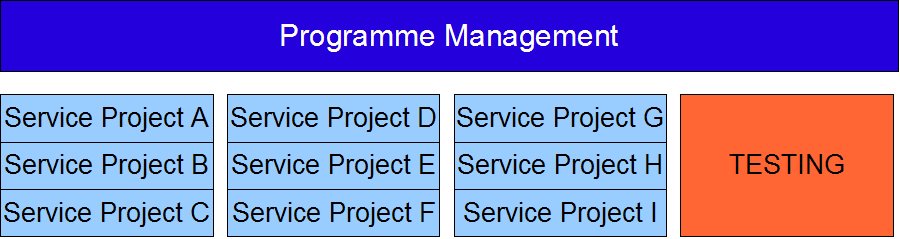 This is and example of a 9 service project in this sort of approach. Some of these services will be business services, some will be technical, and of course the highest risk elements should come at the start. Unfortunately we still have the massive tailend of Testing to worry about which is where the concept of "Project UAT" can come in, the approach here is to sell UAT for each project as an increase in formalism, so getting people testing earlier is all about adding extra process to the project. The reality is of course that this testing reduces your risk as you are getting eyes on the solution earlier. This can then be used to either reduce the testing at the end, or demonstrate your genius by waltzing through it without an issue.
This is and example of a 9 service project in this sort of approach. Some of these services will be business services, some will be technical, and of course the highest risk elements should come at the start. Unfortunately we still have the massive tailend of Testing to worry about which is where the concept of "Project UAT" can come in, the approach here is to sell UAT for each project as an increase in formalism, so getting people testing earlier is all about adding extra process to the project. The reality is of course that this testing reduces your risk as you are getting eyes on the solution earlier. This can then be used to either reduce the testing at the end, or demonstrate your genius by waltzing through it without an issue.Lets be clear though, I'm not advocating this as the best approach, just as a way to get Waterfall project managers and organisations working in a more iterative way using Services as the mechanism. Its not rocket science and its not ideal but until there are no more muppets posting things about Waterfall being an option and I stop seeing projects being delivered in a waterfall way its at least better that what was there before. And if you can keep all your waterfall projects inside a month then its hard to tell the difference from agile.
Monday, March 13, 2006
Product vendors and capabilities, another type of bus?
Following up from an earlier post on the different types of ESB I've noticed that lots of the vendors (IBM, Oracle, BEA to name but three) are talking about the way you can plug-and-play the products in their stack thanks to their ESB functionality. This is also the sort of gap that JBI tries to address, in that its not really an ESB that is about end-user services calling each other, its about having end-user services able to call other end-user services residing in different "capabilities". From the SOA Reference model, which defines a service as a way to access capabilities this means that considering a BPEL engine as a service is all well and good, but I'd argue that while from a PRODUCT perspective it provides that service from a development perspective its just a set of capabilities which a service can take advantage of, for instance by using it to execute a BPEL process.
So while its a good thing that vendors are using the power of their bus to enable product replacement and better integration, certainly the goal of JBI, this shouldn't be confused architecturally with the Integration and Business Bus problems talked about earlier. In reality these "capability busses" sit inside an SOA application and provide the glue between different tiers, e.g. Business Service to Process Service, and like all good joins if they are done well you shouldn't care about it.
So now we are up to there different Enterprise Service Bus types, the Integration, Business and now Capability Bus, all with a different architectural purpose even if they can actually be the same product. Its important to keep these things separate because they have different intentions and goals, if you start confusing the metaphors and approaches you are liable to end up with a very confused mess.
So while its a good thing that vendors are using the power of their bus to enable product replacement and better integration, certainly the goal of JBI, this shouldn't be confused architecturally with the Integration and Business Bus problems talked about earlier. In reality these "capability busses" sit inside an SOA application and provide the glue between different tiers, e.g. Business Service to Process Service, and like all good joins if they are done well you shouldn't care about it.
So now we are up to there different Enterprise Service Bus types, the Integration, Business and now Capability Bus, all with a different architectural purpose even if they can actually be the same product. Its important to keep these things separate because they have different intentions and goals, if you start confusing the metaphors and approaches you are liable to end up with a very confused mess.
Sunday, March 12, 2006
XSLT... mapping from XML data to SVG
Well I've just found myself doing some more transformation work, pretty easy stuff translating a basic schema which was a series of nested "node" objects, each with a label. And using it to create an SVG tree based render of the information. First port of call was to try and cheat by using an automatic mapping tool, after all XSLT is the future of transformation isn't it?
So the first challenge was that SVG doesn't have a schema it has DTDs! A quick "generate schema" request in XMLSpy to give myself something to aim at. So now we have a source schema that looks like
And we are aiming at the wonder that is SVG, so basically we need the "text" and "polyline" elements as the target, and we are going for fixed positioning. This means we have two basic challenges
Well in Java, using for example JAX-B, I know I could knock out the code in a couple of minutes as its just about recursion and have a return value from a function to give the current Y position. Now in XSLT you have the concept of variables... but they aren't actually variable you can't change them!. What is required is to declare a variable which calls a function etc etc, this then gets you a variable that is assigned based on a calculation.
Recursion is slightly easier as all you need to do is "call-template" on a previously declared template. This is coding from the good old "C" days but with the worst syntax imaginable. And here is the challenge, if XSLT really is to be a transformation language then it needs to be, in the same way as BPEL, to be an execution language rather than the definition language. So it needs a BPMN or even a standard programming language that is "compiled" down to XSLT.
Any way after a bit of work (a few hours) I got the mapping done, remember this is basically just turning a nested structure into a flat structure and connecting the nodes with lines.
Which gives us
Now its pretty compact and it gets the job done, but this was hand-coded as the visual tools were more complex that writing it myself... this is worrying as more people try and do XSLT for ESBs and the like in that type of visual tool, they aren't liable to be creating the most efficient, or indeed the most complete, transformations.
I wasn't too worried about these transformation engines relying on XSLT and the visual mappers, after all how often do you have to map a hierachy into a flat structure? I can see quite a few times where this would crop up, for instance creating loading information for instance when you want to bulk load into a database.
This then got me thinking about even greater complexities that occur and how will XSLT mappers help people, or are we all going to end up coding in XSLT? I hope not as XSLT is a plain RUBBISH programming language. It would be good to create a set of mapping challenges that will push the latest technologies to the max and see if they help or hinder the creation of decent mappings.
XSLT programming is like coding through mud, its not a rewarding experience.
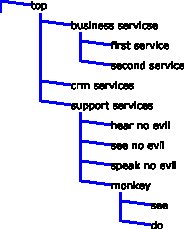
For those interested the final image (as a png so everyone can see it) is

So the first challenge was that SVG doesn't have a schema it has DTDs! A quick "generate schema" request in XMLSpy to give myself something to aim at. So now we have a source schema that looks like
<?xml version="1.0" encoding="UTF-8"?>
<node label="top" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<node label="business servicse">
<node label="first service"/>
<node label="second service"/>
</node>
<node label="crm services"/>
<node label="support services">
<node label="hear no evil"/>
<node label="see no evil"/>
<node label="speak no evil"/>
<node label="monkey">
<node label="see"/>
<node label="do"/>
</node>
</node>
</node>
And we are aiming at the wonder that is SVG, so basically we need the "text" and "polyline" elements as the target, and we are going for fixed positioning. This means we have two basic challenges
- Recursion - Nodes have nodes etc etc
- Position is based on the position of the previous element - X is based on the depth in the node and Y is based on the Y of the previous element
Well in Java, using for example JAX-B, I know I could knock out the code in a couple of minutes as its just about recursion and have a return value from a function to give the current Y position. Now in XSLT you have the concept of variables... but they aren't actually variable you can't change them!. What is required is to declare a variable which calls a function etc etc, this then gets you a variable that is assigned based on a calculation.
Recursion is slightly easier as all you need to do is "call-template" on a previously declared template. This is coding from the good old "C" days but with the worst syntax imaginable. And here is the challenge, if XSLT really is to be a transformation language then it needs to be, in the same way as BPEL, to be an execution language rather than the definition language. So it needs a BPMN or even a standard programming language that is "compiled" down to XSLT.
Any way after a bit of work (a few hours) I got the mapping done, remember this is basically just turning a nested structure into a flat structure and connecting the nodes with lines.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:svg="http://www.w3.org/2000/svg" xmlns:fn="http://www.w3.org/2005/xpath-functions" exclude-result-prefixes="xs fn">
<xsl:output method="xml" encoding="UTF-8" indent="yes"/>
<xsl:variable name="xOffset">4</xsl:variable>
<xsl:variable name="yOffset">2</xsl:variable>
<xsl:variable name="depthCurrent">0</xsl:variable>
<xsl:template name="processNode">
<xsl:param name="depth"/>
<xsl:param name="yRoot"/>
<xsl:variable name="x" select="$depth * $xOffset"/>
<!-- Count the number of previous nodes, add on the depth as the parents are truly preceding as they haven't been closed and create the Y value -->
<xsl:variable name="y" select="(count(preceding::node) + $depth) * $yOffset"/>
<!-- loop through each of the labels, there is only one however -->
<xsl:for-each select="@label">
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="{$x}" y="{$y}">
<xsl:value-of select="."/>
</svg:text>
<!-- Now draw the lines, these run from the parents down to the element, hence the use of Y root -->
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="{$x - (0.75 * $xOffset)}, {$yRoot + (0.2 * $yOffset)}, {$x - (0.75 * $xOffset)}, {$y - (0.4 * $yOffset)}, {$x}, {$y - (0.2 * $yOffset)} "/>
</xsl:for-each>
<!-- for each of the nodes in this one repeat the process passing an increased depth to the child -->
<xsl:for-each select="node">
<xsl:call-template name="processNode">
<xsl:with-param name="depth">
<xsl:value-of select="$depth + 1"/>
</xsl:with-param>
<xsl:with-param name="yRoot">
<xsl:value-of select="$y"/>
</xsl:with-param>
</xsl:call-template>
</xsl:for-each>
</xsl:template>
<xsl:template match="/node">
<svg:svg xmlns:svg="http://www.w3.org/2000/svg">
<svg:g transform="translate(10,10) scale(10)">
<xsl:call-template name="processNode">
<xsl:with-param name="depth">0</xsl:with-param>
<xsl:with-param name="yRoot">0</xsl:with-param>
</xsl:call-template>
</svg:g>
</svg:svg>
</xsl:template>
</xsl:stylesheet>
Which gives us
<?xml version="1.0" encoding="UTF-8"?>
<svg:svg xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:svg="http://www.w3.org/2000/svg">
<svg:g transform="translate(10,10) scale(10)">
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="0" y="0">top</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="-3, 0.4, -3, -0.8, 0, -0.4 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="4" y="2">business servicse</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="1, 0.4, 1, 1.2, 4, 1.6 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="8" y="4">first service</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="5, 2.4, 5, 3.2, 8, 3.6 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="8" y="6">second service</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="5, 2.4, 5, 5.2, 8, 5.6 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="4" y="8">crm services</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="1, 0.4, 1, 7.2, 4, 7.6 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="4" y="10">support services</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="1, 0.4, 1, 9.2, 4, 9.6 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="8" y="12">hear no evil</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="5, 10.4, 5, 11.2, 8, 11.6 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="8" y="14">see no evil</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="5, 10.4, 5, 13.2, 8, 13.6 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="8" y="16">speak no evil</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="5, 10.4, 5, 15.2, 8, 15.6 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="8" y="18">monkey</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="5, 10.4, 5, 17.2, 8, 17.6 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="12" y="20">see</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="9, 18.4, 9, 19.2, 12, 19.6 " />
<svg:text style="text-anchor: left; font-size: 1" text-anchor="start" font-size="1" x="12" y="22">do</svg:text>
<svg:polyline fill="none" stroke="blue" stroke-width="0.2" points="9, 18.4, 9, 21.2, 12, 21.6 " />
</svg:g>
</svg:svg>
Now its pretty compact and it gets the job done, but this was hand-coded as the visual tools were more complex that writing it myself... this is worrying as more people try and do XSLT for ESBs and the like in that type of visual tool, they aren't liable to be creating the most efficient, or indeed the most complete, transformations.
I wasn't too worried about these transformation engines relying on XSLT and the visual mappers, after all how often do you have to map a hierachy into a flat structure? I can see quite a few times where this would crop up, for instance creating loading information for instance when you want to bulk load into a database.
This then got me thinking about even greater complexities that occur and how will XSLT mappers help people, or are we all going to end up coding in XSLT? I hope not as XSLT is a plain RUBBISH programming language. It would be good to create a set of mapping challenges that will push the latest technologies to the max and see if they help or hinder the creation of decent mappings.
XSLT programming is like coding through mud, its not a rewarding experience.
For those interested the final image (as a png so everyone can see it) is
Thursday, March 09, 2006
"Semantic" Web Services... not actually Semantic
Now the semantic web as championed by non other than Tim Berners-Lee is one of those next generation things. Since talking about Web Service 2.0 I've spent more time look at the Semantic web stuff and I'm beginning to spot something. Its actually not semantics of Web Services at all, its just the semantics of the information passed, and there is a massive difference.
Semantics is defined as
In the main, semantics (from the Greek semantic, or "significant meaning," derived from sema, sign) is the study of meaning, in some sense of that term.
Now the TBL version is aimed at the web itself which is about the exchange of information and hence those semantics (meanings) refer to the information exchange. With Services its a completely different story however as they are not simply about information exchange but also about the effect that the service has. This means that a semantic definition of a service (i.e. one that describes its meaning) must including not only the semantics of the information exchange but also the semantics of its function and its this element that all of the current Semantic web services work seems to "nicely" avoid. The problem here is that while the Semantic web is a powerful concept when trying to traverse and make sense of information the current efforts do little, or nothing, to help when trying to make sense of the effects or functions of services.
So it is a misuse of the term "Semantic" to apply to web services when the only definition is of the information being exchange. Until the semantics can ascribe meaning to the functional effects of a service (e.g. "Don't call me at 2am I'll be down for backups", "before calling me you have to have done a fraud check", "after I finish there will be no people called John in the system" etc) then they aren't actual defining the meaning of Services.
So the current status is:
Semantic Web - cool
Semantic Web Services - fraud.
Semantics is defined as
In the main, semantics (from the Greek semantic, or "significant meaning," derived from sema, sign) is the study of meaning, in some sense of that term.
Now the TBL version is aimed at the web itself which is about the exchange of information and hence those semantics (meanings) refer to the information exchange. With Services its a completely different story however as they are not simply about information exchange but also about the effect that the service has. This means that a semantic definition of a service (i.e. one that describes its meaning) must including not only the semantics of the information exchange but also the semantics of its function and its this element that all of the current Semantic web services work seems to "nicely" avoid. The problem here is that while the Semantic web is a powerful concept when trying to traverse and make sense of information the current efforts do little, or nothing, to help when trying to make sense of the effects or functions of services.
So it is a misuse of the term "Semantic" to apply to web services when the only definition is of the information being exchange. Until the semantics can ascribe meaning to the functional effects of a service (e.g. "Don't call me at 2am I'll be down for backups", "before calling me you have to have done a fraud check", "after I finish there will be no people called John in the system" etc) then they aren't actual defining the meaning of Services.
So the current status is:
Semantic Web - cool
Semantic Web Services - fraud.
Subscribe to:
Posts (Atom)