One of the big questions of SOA is what it does to the normal IT organisations. I've blogged a couple of times about how SOA helps create a series of
smaller projects inside a larger programme which gives you smaller teams and helps (even without using Agile methods) create more
Agile projects.
This move towards service development pretty much demands that you move towards a service oriented organisation. To ensure that services are developed effectively and maintained effectively you don't want to keep having lots of different people having to learn how the service works and as SOA is about becoming more business oriented you need to maintain that knowledge at all levels, this means dedicating people to specific areas and services.
This means changing the IT organisation and its structure to match the business service architecture, including treating
IT as a business domain. Taking the Level 0, Level 1, Level 2 approach from the SOA methodology this drives through into the organisation structure.
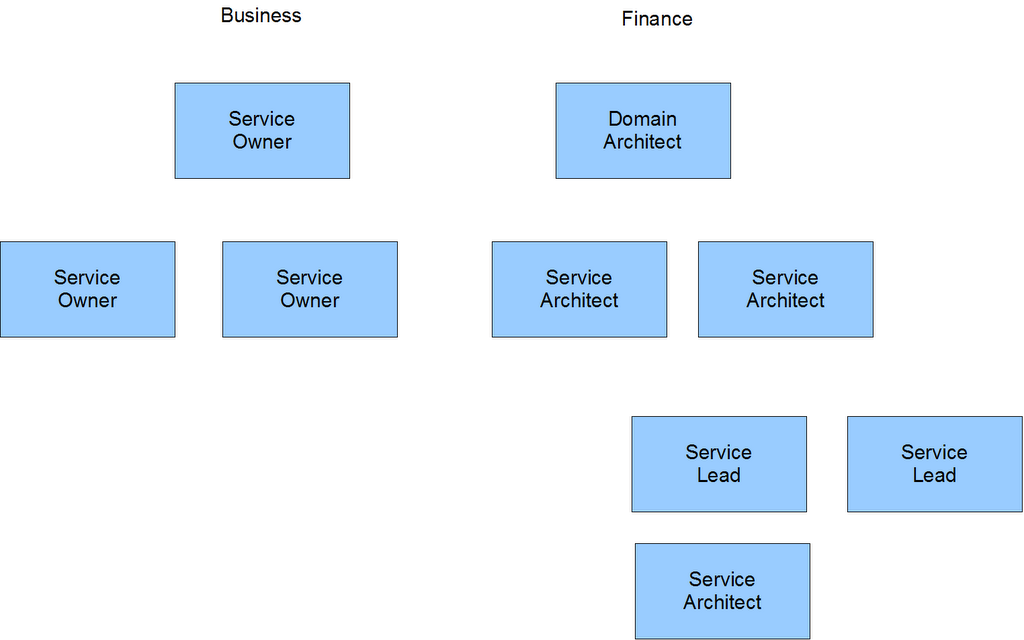
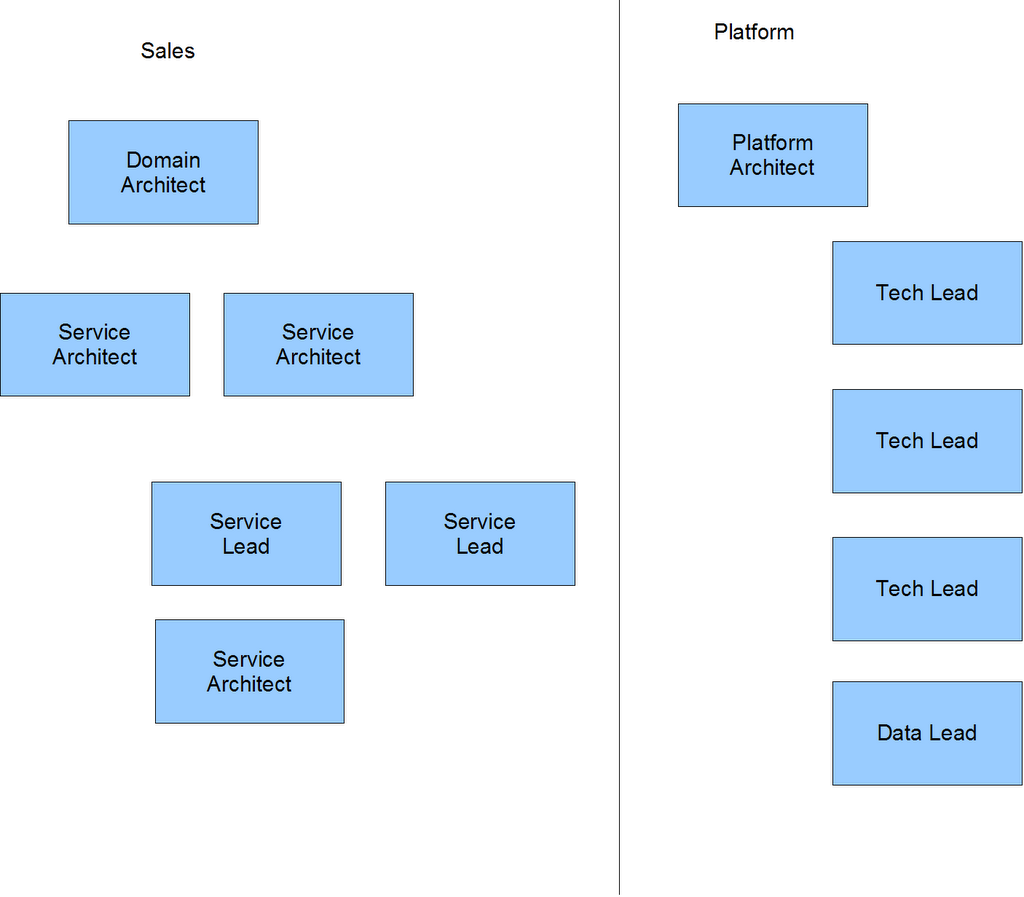
There are three distinct areas in the org chart
- Business - The business owners of the various services, potentially delegating authority on lower level services to people inside IT while retaining a sign-off role
- Service Delivery - The part of IT that delivers the business services
- Platform Delivery - The part of IT that delivers the underlying platforms and the technical services that are required to deliver the business services.
Each of these has different KPIs, and the Service Delivery teams have two sets of measures.
Business - Must commit to a long term view of IT if they want an IT organisation that evolves in the way they want and reduces the overall cost of IT and gives them the dynamic change they want. This means agreeing to committed plans that enable multi-year planning, not multi-week. It also means that the business must be aware that if they do want to do something tactical that it will require an "offset" investment.
Platform Delivery -Responsible for defining the IT standards and delivering the mechanism for measuring and enforcing them. This means providing the base platforms and functionality. It is this team that is responsible for defining what technical tools should be used and how they should be implemented.
Service Delivery - Measured by the business against delivery and by platform against quality.
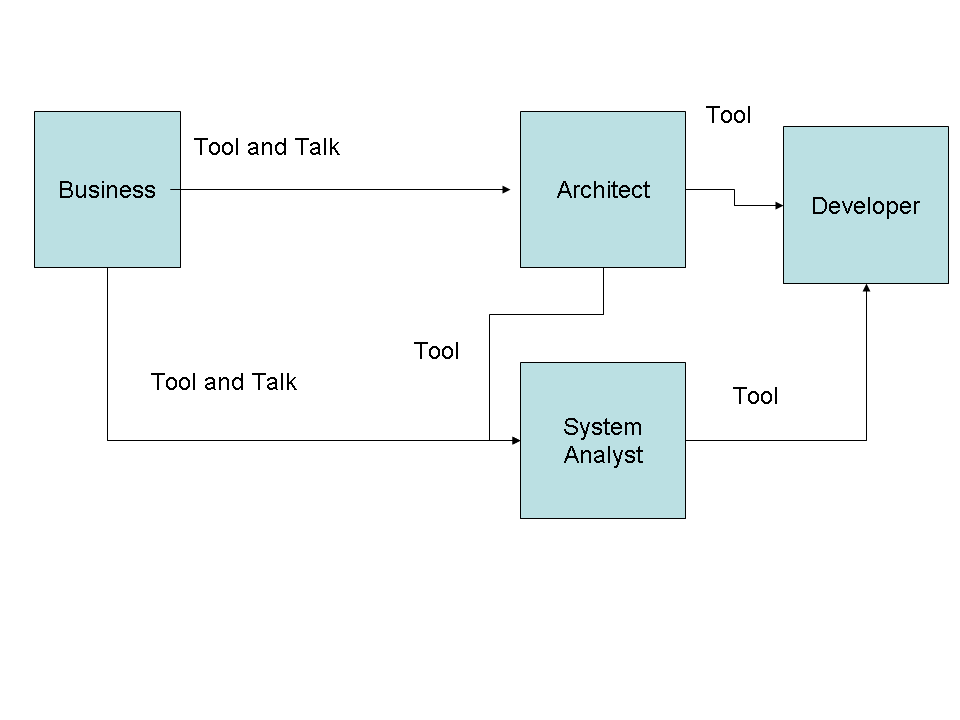
Business Services Each service has two "heads", one from the business, one from IT. The business person is responsible for defining what the service
is the IT person is responsible for how it is delivered. Questions like "XML Schema" et al are the responsibility of IT.
Within a Service (e.g. Level 1 Services inside Level 0) the IT leader is responsible to the leader of the level above.

And for each area you have a similar structure (depending on the service structure)

The most senior architect within a given area is responsible to the platform team for the quality of their delivery. This architect is responsible for working with the platform team to determine the best technology approach. The business service architect knows the drivers and change required, and the platform architect aims to deliver a consistent infrastructure so together they've got to select the right solution to deliver both the service, and the overall estate.

The Platform team provides the technical expertise to make sure that the business services are delivered correctly. It might even include some common technical elements that are required across all the different service areas, and critically someone to make sure that the data being collected is of a decent quality and at least vaguely consistent! The platform team isn't service based in the way that others are, its capability based, so in here you get the testing teams, deployment teams and all of those bits that everyone requires.
Then once we have this all in place and we've targeted people as owners (and please do note that one architect or business person can support multiple services within a domain if they are all relatively small) we actually need to get onto development.
The recommendation here isn't to have every service with a dedicated delivery team, you just want a couple of core people to be permanently assigned, the architect, analyst and probably the technical lead. It is a good idea to have developers at least generally assigned to one service area (Level 0 or Level 1) of course.

When you have a programme kicking off the first job is obviously to determine the services that are impacted by the programme. This means that project/programme managers live elsewhere in the organisation and are assigned to programmes as they are kicked off. Once this is done the programme manager and the lead service architects from the impacted services (and hint of the day
restricting programmes to one top level service makes things easier) and decides on the right approach and delivery method(s). Then you assign the resources to the programme which will then be directed into the various service teams.
The programme team is responsible for the overall requirements and delivery, and making sure that the various service changes are integrated together and the quality of the final programme delivery. The development effort is led by the service lead (or architect) with resources assigned by the programme manager.
If platform changes are required then its pretty much the same except that it includes assignment of resources into the platform team. Once the programme is finished its transitioned into standard running and the development teams are wound down.
During the delivery the service leads are responsible to their senior architect and the platform architect for the quality of the delivery. The testing team that is assigned comes from the platform team and is responsible for ensuring that the delivery meets the platform standards. This dual responsibility is aimed at reducing the "rush to live" quality cutting that reduces the long term flexibility of the solution. Sure sometimes the programme has to go live, but again this means that it needs some offset funds, the things the business committed to up front.
The key here is that everyone is bought into the service architecture, the governance is there to enforce what needs to be done and it does that by taking that service architecture as its base. This makes sure that SOA isn't just a series of powerpoints, its baked into how IT operates and delivers.
Technorati Tags: SOA, Governance, Service Architecture