A very short while ago I made a post about the starting point for SOA and in the follow-up I made a comment that I wasn't a big fan of canonical data models, and I was asked to clarify why, so here goes.
First off lets agree what we mean by this and I'll take this
Taking the manufacturing service Level 0 as out start
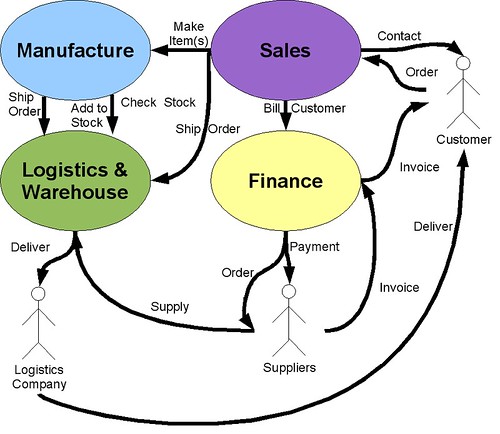 and thinking about product and customer as our two data elements to worry about. There are three approaches here, all of which could be called canonical to some degree but which represent very different approaches to the solution.
and thinking about product and customer as our two data elements to worry about. There are three approaches here, all of which could be called canonical to some degree but which represent very different approaches to the solution.
Just the facts
The first is the one I've used most often to success in this area, and its focus is all about the interactions between multiple services. The rule here is basically common demoninator, the objective is to find the minimum set of data that can be used to effectively communicate between areas on a consistent basis. The goal here isn't that this should be used on 100% of occasions but that it represents 70-80% of the interactions.
In this model we might even get to the stage where its ProductID and CustomerID that are shared and we have a standard provisioning approach for the two to ensure that IDs are unique. But most often its a small subset that enables each service to understand what the other is talking about and then translate it into its own version. So in this model the "canonical" form is very small, really just a minimal reference set. This does mean that sometimes conversations have to take place outside of this minimal reference set, and that is fine, but its more costly so the people making that call need to be aware that now they are completely responsible for managing change of that interaction.
So in this model we might say that all product elements are governed by the productID, customer consists of Name and Address, but when sales talk to finance to bill a customer for an order they also include the product description from their marketing literature to help it make sense on the invoice. Here we would model this extra bit of information either as an extension to the previous data model, or just consider it bespoke for that transaction. This would mean that the sales service team would now be responsible for the evolution of that data description rather than using the global model which would be owned and maintained... well globally. The objective when communicating is to use this minimal reference set as much as possible, as this reduces effort, and the goal of the team that maintains it is to keep it small so its easier for them.
This model is paticularly effective in data exchange projects like reporting or on base transactional elements, but its the one I've seen used most effectively especially when combined with strong governance and enforcement around the minimal reference set. A great advantage of this model is that it reduces the risk of work being done in the wrong place, if all you have is CustomerID you are unlikely to undertake a massive fraud profiling project, something better off left to finance.
When you talk, we listen
The next approach, and already getting into dangerous territory IMO is to create a superset of all interactions between services. In this world the goal is to capture a canonical form that represents 100% of the possible interactions between services. Thus if a service might need 25 fields of product information then the canonical form has those 25 fields. The problem with this model is that there is a lot of crap flying about that is just there for edge cases. It can be made to work but it makes day-to-day operations harder and tends to lead to blurring of boundaries between areas/services and increases the risk of duplicate functionality. Its also a real issue of information overload. What I've tended to see happen in this model is that people start adding fields "incase" to the model and also start consuming and operating on fields "because they can". This isn't sensible.
I'd like my project to fail please
The final approach is the mythical "single canonical form" this beast is the one that knows everything, its like enterprise but even worse. This one creates a single data model that represents not only the superset of interactions, but the superset of internals as well. So it models both how finance and manufacturing view products and lobs them together, considers how sales and distribution view customer and lobs them together. Once this behemouth is created it then mandates this as the interaction between the areas with (in my experience) disasterous consequences. Its too complex, it removes all boundaries and controls and it ends up with ridiculous information exchanges where both parties known how internally the two areas operate. When external parties are brought into the mix it gets ever more complicated and fragile.
Summary
So I'm not 100% against canonical in terms of an intermediary for data exchange, but I do think that a canonical form needs to be kept very small and compact and that exchanges outside of that canonical form must be allowed for and managed. In the same way as there isn't an enterprise service bus that does everything there is equally no single canonical form that works everywhere. Flexibility comes from mandation for certain elements and increased costs for stepping outside, but stepping outside has to be allowed to enable systems, people and organisations to operate effectively.
Technorati Tags: SOA, data modelling, Service Architecture
First off lets agree what we mean by this and I'll take this
As the definition. I've seen, and led, quite a few projects that have used a canonical data model, and for some things its worked and for lots its failed (of course the ones I led were the ones that worked :) ). So its not that canonical forms are a really bad thing, its just that they aren't the ultimate solution.Therefore, design a Canonical Data Model that is independent from any specific application. Require each application to produce and consume messages in this common format.
Taking the manufacturing service Level 0 as out start
and thinking about product and customer as our two data elements to worry about. There are three approaches here, all of which could be called canonical to some degree but which represent very different approaches to the solution.Just the facts
The first is the one I've used most often to success in this area, and its focus is all about the interactions between multiple services. The rule here is basically common demoninator, the objective is to find the minimum set of data that can be used to effectively communicate between areas on a consistent basis. The goal here isn't that this should be used on 100% of occasions but that it represents 70-80% of the interactions.
In this model we might even get to the stage where its ProductID and CustomerID that are shared and we have a standard provisioning approach for the two to ensure that IDs are unique. But most often its a small subset that enables each service to understand what the other is talking about and then translate it into its own version. So in this model the "canonical" form is very small, really just a minimal reference set. This does mean that sometimes conversations have to take place outside of this minimal reference set, and that is fine, but its more costly so the people making that call need to be aware that now they are completely responsible for managing change of that interaction.
So in this model we might say that all product elements are governed by the productID, customer consists of Name and Address, but when sales talk to finance to bill a customer for an order they also include the product description from their marketing literature to help it make sense on the invoice. Here we would model this extra bit of information either as an extension to the previous data model, or just consider it bespoke for that transaction. This would mean that the sales service team would now be responsible for the evolution of that data description rather than using the global model which would be owned and maintained... well globally. The objective when communicating is to use this minimal reference set as much as possible, as this reduces effort, and the goal of the team that maintains it is to keep it small so its easier for them.
This model is paticularly effective in data exchange projects like reporting or on base transactional elements, but its the one I've seen used most effectively especially when combined with strong governance and enforcement around the minimal reference set. A great advantage of this model is that it reduces the risk of work being done in the wrong place, if all you have is CustomerID you are unlikely to undertake a massive fraud profiling project, something better off left to finance.
When you talk, we listen
The next approach, and already getting into dangerous territory IMO is to create a superset of all interactions between services. In this world the goal is to capture a canonical form that represents 100% of the possible interactions between services. Thus if a service might need 25 fields of product information then the canonical form has those 25 fields. The problem with this model is that there is a lot of crap flying about that is just there for edge cases. It can be made to work but it makes day-to-day operations harder and tends to lead to blurring of boundaries between areas/services and increases the risk of duplicate functionality. Its also a real issue of information overload. What I've tended to see happen in this model is that people start adding fields "incase" to the model and also start consuming and operating on fields "because they can". This isn't sensible.
I'd like my project to fail please
The final approach is the mythical "single canonical form" this beast is the one that knows everything, its like enterprise but even worse. This one creates a single data model that represents not only the superset of interactions, but the superset of internals as well. So it models both how finance and manufacturing view products and lobs them together, considers how sales and distribution view customer and lobs them together. Once this behemouth is created it then mandates this as the interaction between the areas with (in my experience) disasterous consequences. Its too complex, it removes all boundaries and controls and it ends up with ridiculous information exchanges where both parties known how internally the two areas operate. When external parties are brought into the mix it gets ever more complicated and fragile.
Summary
So I'm not 100% against canonical in terms of an intermediary for data exchange, but I do think that a canonical form needs to be kept very small and compact and that exchanges outside of that canonical form must be allowed for and managed. In the same way as there isn't an enterprise service bus that does everything there is equally no single canonical form that works everywhere. Flexibility comes from mandation for certain elements and increased costs for stepping outside, but stepping outside has to be allowed to enable systems, people and organisations to operate effectively.
Technorati Tags: SOA, data modelling, Service Architecture
9 comments:
I'm currently involved in exactly this discussion with one of our clients. What we currently favor is to create a superset of all possible attributes of an entity, but to not force the services to use all attributes. The thing we suggest to standardize, though, is the representation of individual attributes.
The problem with supersets though is that people will start using different subsets of that superset so I'm not sure you've not really gained a great deal. The challenge is not just the syntax but the semantics of the elements and what I've observed on supersets is that people have different understandings of what gets done where. Even with supposedly standardised systems like SAP -> SAP I've seen completely different mechanisms for handling product information, but within a single data structure.
This is why I like subsets which take a real genius to misunderstand.
I would ideally like to take it further, the minimal reference model should just be the objects' 'type' and I'm using types in the loosest possible way and a global id for that type. If a system needs more information than the type and id (which it surely will) then it can get it itself, or possibly the mediation layer can enrich the data at service interface invokation time.
The trouble with trying to be helpful to the invokee is firstly governance, it won't be long before you end up with SCF by stealth unless you keep a tight grip on your team/code base and secondly you are making assumptions about the service implementation both the currently implementation and all future incarnations. What if the invokee is rewritten and no longer needs some of the data being passed to it; how is the invoker to know? You end up with a situation where redundant information is being passed around.
I'm sure the is an analogous to the Law of Demeter in some way, what do you think?
The risk with data enrichment in the middleware is that it can quickly spiral into something more complex, including decision based content enrichment. Oracle have done some nifty work recently (not sure if its in the products yet though) around passing IDs around and having the information "magically" appear as you need it. That reminds me I need to look into that.
I basically agree with your points, but as my client originally wanted to create a "real" enterprise data model and mix this concept with the canonical data model, we're happy with a small victory :-)
As ever the way in IT, first we have to convince them to shoot themselves in the foot with a gun, rather than by using heavy artilery :(
Here's a post on the same topic on tips to create canonicals.
http://blogs.ittoolbox.com/eai/business/archives/tips-for-building-the-common-information-7517
What do you mean by "interal"?
Hey, nice article - thanks for sharing. Do you have any examples of canonical forms in real world business models?
Thanks,
James
Post a Comment